

Fully local and fully private GenAI copilot that runs on edge devices

Infrastructure
Runs on CPU, no GPU required

Infinite Tokens
Since the model runs on your local edge device, you can input as many tokens as you like without incurring consumption costs

Privacy
Fully local inferencing means that your data stays on your laptop
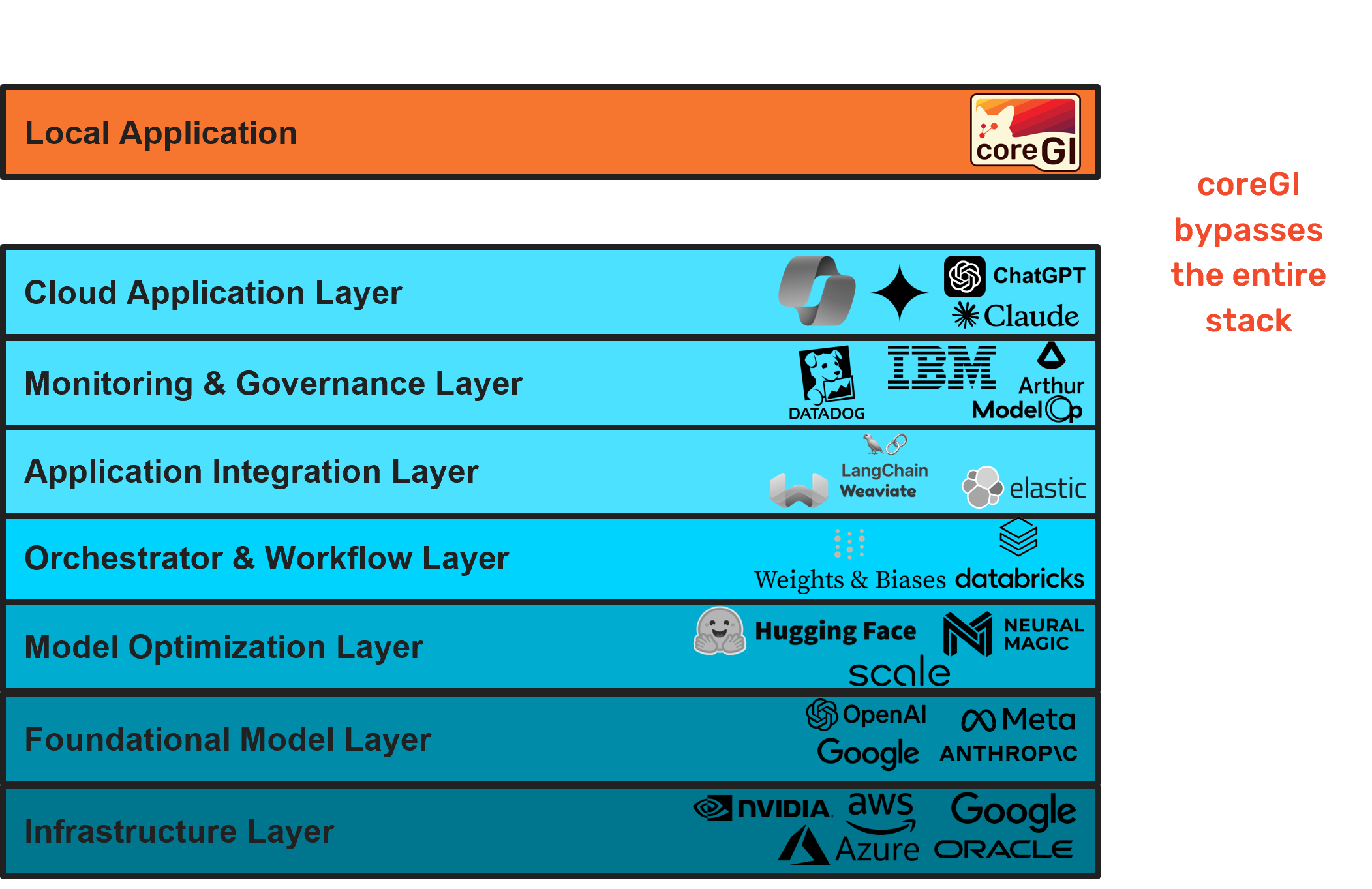
Seamless Adoption
Skip the entire GenAI tech stack with apps that run locally.
Quantum-Inspired Model Compression
Tensor network LLMs enable flagship model performance on CPU/edge devices reducing consumption cost drastically

coreGI Tensor Network Large Language Model
Interested in trying out our product? Join the waitlist!